开元棋牌(中国)官网入口 DeepSeek再放大招,国产大模子坐不住了
文 | 新眸,作家 | 李小东
夙昔一年多,大模子圈每季度至少阅历一次牌面重洗。有东谈主在多模态端连出三张底牌,有东谈主在Agent赛谈一把梭哈,还有东谈骨干脆掀了桌子,把模子拆成零件来卖。
但扫数东谈主王人在等一个东谈主出牌。
这东谈主一年多没动静。2025年1月R1发布之后,他就像从牌桌上清除了。中间V3.1、V3.2、FlashMLA、DualPath这些星星落落的更新,充其量算在桌下换了一手牌,没东谈主知谈他手里到底攥着什么。
4月24日,DeepSeek终于把牌撂下来了——V4预览版认真上线并开源,两个版块:V4-Pro和V4-Flash。
Pro对标顶级闭源。Agent Coding模式下,里面测评体验优于Sonnet 4.5,委用质料接近Opus 4.6非念念考模式。寰球学问测评大幅开头其他开源模子,仅稍逊于Gemini Pro 3.1。数学和代码推感性能上,官方称“卓绝刻下扫数已公开评测的开源模子”。
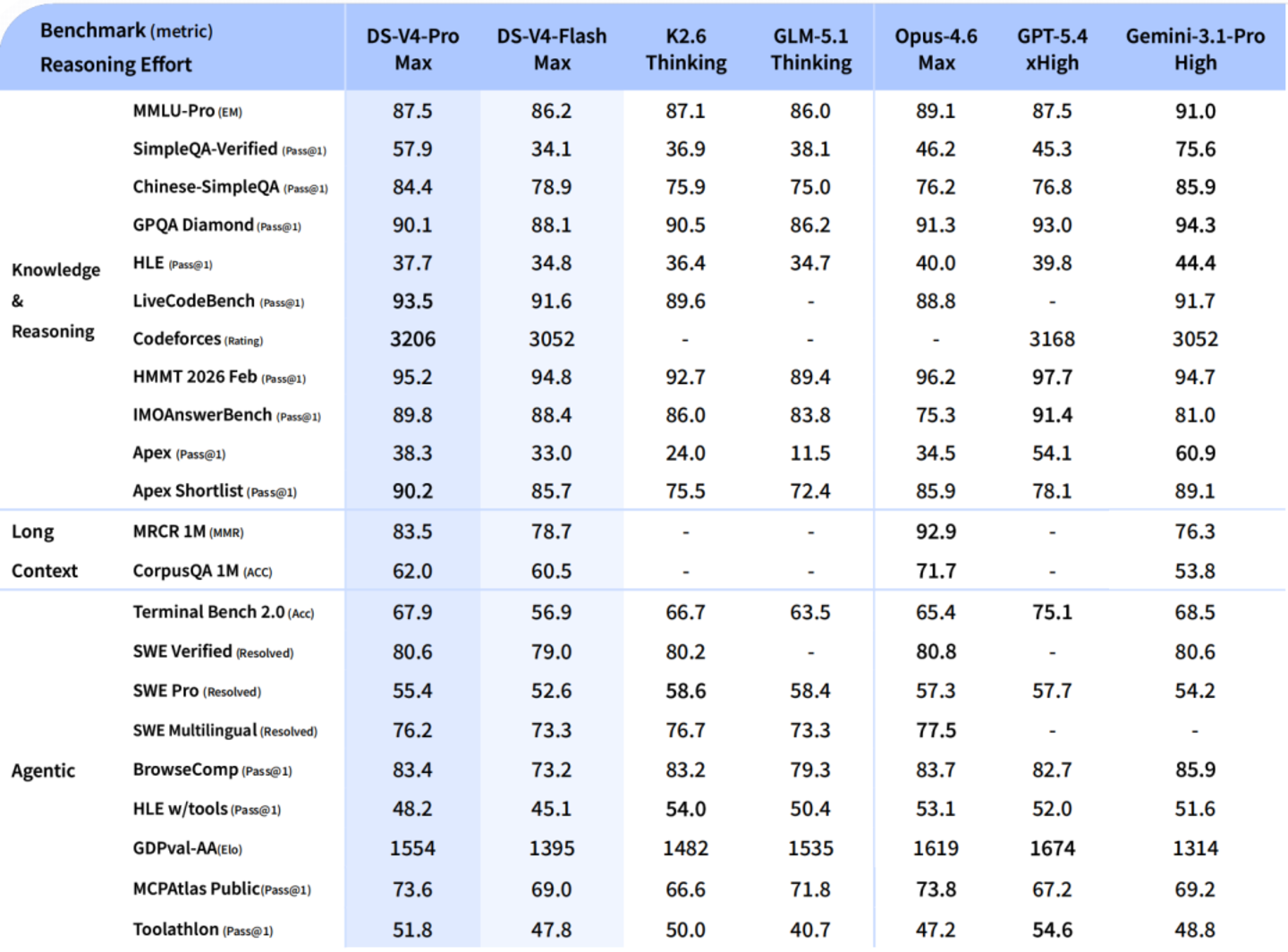
Flash是轻量版,推忠良商接近Pro,但参数和激活更小,API反馈更快,资本更低。两款王人辅助百万token凹凸文——况且是标配。
问题来了:一家公司,在同业豪恣赛马圈地的十五个月里基本千里默,一起始却径直把我方钉回了行业锚点,这说明什么?
说明牌桌上的东谈主根底没离开过。他仅仅换了一种布置。
01 架构的延续性转换
要聚首V4,先赢得看V3。
2024年底,其时大模子行业的主流叙事照旧“参数越大越强”。历练一个大几千亿参数的模子,资本动辄千万好意思元起步。DeepSeek V3用6710亿总参数、每次推理激活37B众人的MoE架构,把单次历练资本压到了500万好意思元出面。
不靠砍参数目,靠MoE路由政策、DSA防护力机制和工程层面的极致优化,说白了,把每一分算力王人花在刀刃上。
V4走的照旧这条路,但走到了更远的处所。
时期规格上,V4完满版总参数跃升至1.6万亿,2850亿的Lite版动作更经济的选项。防护力机制升级为DSA2,整合了DeepSeek V3/R1中的DSA想象,同期引入本年头论文中提议的NSA寥落防护力决议。MoE系统启用Mega内核结构,每层确立384个众人,每次推理激活其中6个。残差伙同沿用Hyper-Connections决议,这条路在近期的DeepGemm更新中已有预演。
这些名词堆在一齐,新手看着像天书,但业内东谈主一眼就能读出含义:V4是DeepSeek夙昔两年来扫数时期荟萃的集大成。
但最值得存眷的变化,在于它的杀青神态。
V4脱期发布的信得过原因,不是什么bug修不完,而是DeepSeek把整套系统从英伟达生态搬到了华为昇腾芯片上。
这不是换个驱动的事儿。DeepSeek R1当年对英伟达GPU的PTX底层作念了极致优化,这是它“花小钱办大事”的中枢竞争力。PTX是CUDA生态里的中间言语,真切到这层,才把其时能压榨的性能王人压了出来。但转到华为昇腾之后,基于英伟达的扫数工程荟萃全部作废。整套底层代码、退换逻辑、工程体系,要重写一遍。
难度在那处?大模子参数达到万亿级别之后,算力压力从“纯诡计”转向了“系统退换与通讯”。DeepSeek V4诚然通过MoE裁减了单次推理的诡计量,但对内存带宽、芯片间互联、KV Cache惩处的条目反而更高了。
英伟达生态里,Hub上对于H100/B200通过NVLink构建高带宽互联的有计划早已证据,其单节点GPU间带宽可达TB/s级别。昇腾在这些目的上有彰着差距,更多依赖光模块进行跨节点扩展,会引入特等的延迟和同步支拨。软件层面,昇腾的CANN框架在算子掩盖、自动并行、内核交融等方面的纯属度,与CUDA生态仍不是归拢个量级。
代价即是时辰。V4原策动打算本年农历新年或2-3月发布,一齐推到4月才亮相。按路透社的报谈,V4将运行在华为最新的昇腾芯片上,工程师花了多数时辰重写中枢代码。V4策动打算发布两个版块:完满版面向华为昇腾芯片,轻量版可在其他国产芯片上运行。
这件事的真义奈何强调王人不外分。夙昔两年,大模子寰球建了一座宏大工场,扫数的用具、标尺、活水线王人是英文写的。你在这个工场里干活,就必须用别东谈主的用具。英伟达CEO黄仁勋近期的反应很能说明问题,他说DeepSeek基于华为平台的新模子“对好意思国来说将是一个倒霉的收尾”。这话从英伟达雇主嘴里说出来,重量饱胀不轻。
一朝有顶级模子在中国国产硬件上跑通了领会高效的推理,好意思国芯片的护城河就不再闲隙。而在4月24日的发布中,官方已明确恢复,V4不才半年将认真辅助华为算力。
02 推理端启动降价,百万token的平权
架构的优化落到大地,看的是资本。而资本死一火这件事,DeepSeek以前干过一次了。
2025年头,当各家大模子还在拼历练端烧钱速率的时候,DeepSeek V3用一套优化到极致的MoE加DSA架构,把同等参数目级下的历练资本砍到了业内平均水平的几分之一。有褒贬称之为“历练端通缩遗迹”。
但夙昔一年,AI行业的问题仍是从“奈何训出一个好模子”变成了“奈何让好模子被用得起”。2026年中国日均Token调用量结巴140万亿,两年间涨了一千多倍。当调用量以这个速率膨大,推理资本就成了独一的命门。
V4在推理端作念了两谈减法。第一谈在架构层面:防护力机制从密集诡计改为DSA2寥落防护力,Token维度径直作念压缩。官方表述是“比较传统情势,对诡计和显存的需求大幅裁减”。第二谈在精度层面:辅助FP4精度,对显存的条目在FP8基础上再降一半。
路透社此前报谈的推算也佐证了遵循死一火的效果:V4每个token仅激活约370亿参数,推理资本与V3保持在归拢量级。参数目翻了不啻一倍,推理资本却没涨。这意味着大到需要算力集群的企业,小到调用API的创业者,王人能在更大限度的模子上保管临近的预算。
而DeepSeek永远以来的订价也起到了裁减门槛的作用。模子好用,用得低廉,调用量当然陆续增长。反过来陆续分担摊销研发插足,再推动更大限度模子的怒放,变成一个正向飞轮。
这个逻辑夙昔一年在开源模子里跑通了不啻一家,开元棋牌(中国)官网入口V4简略率是这条路上最新的加快器。
V4还有一个容易被漠视的信号:百万token凹凸文成为标配。
一年前,1M凹凸文照旧Gemini独家的王牌,其他扫数闭源模子深广在128K或200K之间,开源生态险些没东谈主碰这个量级。DeepSeek莫得把它包装成高端升值劳动,而是明确文书从今天启动,V4扫数官方劳动的凹凸文默许王人是1M。况且开源。
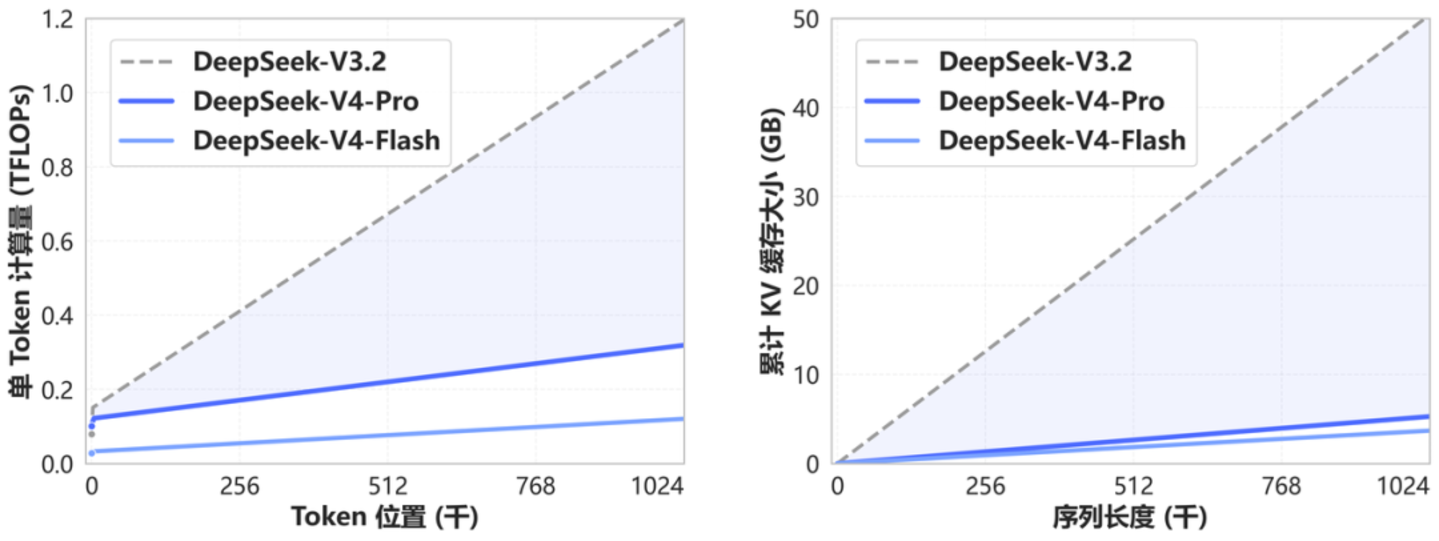
它的时期阶梯也解释得很干脆。用一种全新的防护力机制在token维度上作念压缩,同期互助DSA寥落防护力,径直把传统Attention的诡计量和显存需求量削了下去,使得模子处理1M凹凸文时的实质支拨并不比处理128K高几许,以致不错忽略不计。
此前的决议为了复旧长凹凸文,不时要追加内存、加多缓存层级。而V4把这条路走了个捷径,且仍是怒放给扫数东谈主。
这意味着什么?中小开垦者用零门槛把整本《三体》塞进领导词,法律条约分析不错全文一次性送入模子,长周期多轮Agent调用完全免去牵挂压缩的魔改。
2025年,大模子行业的叙事照旧“智商平权”,开源模子追上闭源,大众王人能用。2026年,叙事进一步延长,变成“使用平权”,好模子不仅要追得上,还得用得起、用得直快。
当把1M凹凸文和Agent智商同期怒放,开垦者的天花板一下子被举高了许多。而这扇门掀开之前,作念Agent的团队光是处理超长凹凸文的牵挂惩处就要花掉一半元气心灵。
03 大厂的错愕和各自的算盘
V4的发布会不是在真空中开的。牌桌上仍是换了不知谈几轮玩家。
大厂这边,各家动作密集到了“每周王人有新东西”的经过。2026年马年春节前后,字节、阿里、腾讯、百度四家累计插足超45亿元,以红包、免单、科技礼品等情势推动AI左右走向全民。
时期竞赛进入胶著气象。2月,阿里、字节、MiniMax密集发布新一代模子产物,MiniMax M2.5、Kimi K2.5、GLM-5等中国模子在OpenRouters上的Tokens挥霍数已排进全球前三。
前不久,腾讯发布混元寰球模子2.0,辅助二次裁剪并径直导入Unity和UE引擎;阿里ATH作事部发布HappyOyster寰球模拟器,辅助高保真动态场景生成。同月,京东探索有计划院开源自研的JoyAI-Image-Edit图像模子,切入了AI空间聚首的中枢难题。
云厂商的模子政策也从“押注一颗独苗”转向了多模子整合。“模子超市”随处吐花,阿里云、百度智能云、腾讯云王人在把多家不同厂商的模子相聚纳入归拢平台,按需分发保举。这背后的逻辑很明晰,大模子正在从研发金钱走向畅达商品,掌捏分发渠谈比领有单一模子的时期上风,阛阓薪金更确信。
而DeepSeek面对的场所比一年前复杂得多。
2026年的Agent蕃昌带来了Token挥霍的狂欢,从OpenClaw到Hermas王人执政归拢个标的用劲,把大模子调用频次推向指数级更高。智谱、MiniMax等厂商凭借海量的API调用在推理端闷声发大财,以致推动了阿里、智谱和MiniMax本身转向闭源。
当敌手的战斗仍是鼓吹到了多模态万能矩阵和业务深融的Agent生态时,单一的基座智商和文本推理仍是不及以组成护城河。V4不再挟制点结巴的孤胆英杰,而是必须同期在开源模子基准、超长凹凸文易用性、推理资本死一火以及国产硬件辅助等多个棋盘上取得上风。
从发布收尾看,V4交出的答卷如实考据了它对当下竞争焦点的聚首。而它面对的中枢锻真金不怕火,其实仍是被精确详细,“荟萃的Prompt手段,王人是基于DeepSeek架构,那在一定经过上会加多开垦者更换模子的资本,变成了隐形的时期订价权”。
时期订价权的经久性,取决于V4发布之后的开源生态运营节拍和买卖模式的政策纵深。
回头看,DeepSeek V3那一次,篡改的是“历练资本”。其时行业共鸣是历练大几千亿参数的模子动辄几千万好意思元,DeepSeek用500万好意思元评释这个数字不错压缩一个量级。之后各家的历练资本预估一齐走低,开源和闭源的资本基线被从头书写。
V4此次作念的是另一件事:它用万亿参数级的模子,把基准智商、百万级凹凸文和Agent智商同期打包、断绝、开源,向行业宣告——资本这一刀接下来砍向推理端。
这对不同玩家的打击是不同的。对重注闭源的大厂来说,压力在于竞争不再仅仅性能对标,而是开源社区把“水电煤”的价钱压穿了之后,闭源要保管溢价变得越来越艰难。
从OpenAI到Anthropic,包括国内闭源巨头,面对Arch Lint的价钱锚点,订价体系只会变得前所未有的透明。对于盯紧基础层算力供需的劳动商来说,当推理遵循大幅普及、能效陆续优化,扫数这个词算力需求的预期反而可能被从头上修。
更深一层的真义在于硬件生态。黄仁勋说“DeepSeek基于华为平台的新模子对好意思国来说将是一个倒霉的收尾”,碰劲点出了这轮AI竞争的中枢,从算法比拼转到系统工程智商比拼,再到硬件生态的绑定与解围。
V4会不会成为第一个信得过跑通国产算力闭环的万亿级大模子,咫尺还莫得定论,但它在“去CUDA化”这条路上至少提供了一种可考据的参照系。
至于DeepSeek我方,融资、东谈主才、买卖化,该面对的问题一个不会少。据上海证券报音问,DeepSeek已启动竖立以来初度外部融资,宗旨估值不低于100亿好意思元,策动打算筹集至少3亿好意思元。首代模子中枢作家之一罗福莉转投小米,R1中枢有计划员、GRPO中枢发明者郭达雅加入字节向上Seed。
大模子赛谈的泼辣在于,你必须在奔驰的列车上边换轮子边踩油门,停驻来哪怕三个月,就可能被甩出牌桌。
DeepSeek停了一年多,这时间对面的东谈主一直在不竭地发牌。咫尺它终于亮出了我方的牌。只看一个开局,赢输还远未到来,但有少量实在无误:这家公司的牌,从V3打到V4,不打散牌,一把王炸。
不管最终谁是赢家开元棋牌(中国)官网入口,这轮牌局的围不雅价值,远远胜过任何一个模子的跑分收尾。
亚搏体育官方网站 - YABO