开元棋牌(中国)官网入口 谷歌Jeff Dean重磅论文:弹性大限制散播式预磨练终于可行了

剪辑|Panda
弹性 AI 预磨练如故鼓动到了下一个前沿!没特无意:来自谷歌。
据先容,他们建议的 Decoupled DiLoCo 是一种改变性的散播式磨练时期,无意哄骗宇宙各地的异构硬件进行磨练,况且即使当硬件发生故障时,系统也不会住手运行!

这项重磅盘问效用激励了粗鄙眷注,论文 Leads 作家之一的 Arthur Douillard 在 X 上的共享推文获取了超 260 万次浏览!
值得细心的是,著名盘问者、Google DeepMind 和 Google Research 首席科学家 Jeff Dean 亦然作家之一。他也发布了多条推文先容这项效用。

推文中,他还回忆了我方 14 年前的一篇一作论文《Large Scale Distributed Deep Networks》。在这篇 NeurIPS 2012 论文中,他们就如故解释大限制磨练和异步时期不错用于磨练相配庞大的神经齐集,并以容错的表情将磨练任务折柳到数千台机器上。

而当今,Decoupled DiLoCo 有望将这个理念简直造成切实可行的大限制工程实施。

论文标题:Decoupled DiLoCo for Resilient Distributed Pre-training
论文地址:https://arxiv.org/pdf/2604.21428v1
配景:限制越大,故障越平方
要持续这项责任的真谛,先要持续当代 AI 磨练的一个根柢窘境。
今天磨练大说话模子,精深取舍一种叫作念 SPMD(单门径多数据)的并行表情。毛糙来说,就像一个工场里通盘工东谈主必须同步操作一条活水线 —— 每个东谈主皆在作念我方那一步,但通盘东谈主必须同期完成,才能鼓动到下一步。任何一个工位出了问题,整条活水线就得停驻来等。
这在小限制下没什么问题。但当集群限制彭胀到数十万乃至数百万块芯少顷,概率就运行作怪了。
论文里有一个凯旋的筹谋:假定每块芯片平均一年才会出一次故障,听起来如故很可靠了。但淌若集群里有 240 万块芯片,通盘这个词集群的平均故障断绝就镌汰到不及一分钟。在这个限制下,硬件故障可弗成再被视为无意了,而是磨练进程中的日常。
现存的搪塞表情,是所谓的「弹性磨练」:检测到某台机器宕机后,从头转化集群确立,用剩余的健康机器络续跑。但这个重确立进程自己就要耗尽多数时分,导致通盘这个词集群在恭候时期无法作念灵验筹谋。
论文的模拟数据败露,在 240 万块芯片的限制下,即使有弹性机制,本色灵验筹谋时分(即「Goodput」,灵验模糊率)也独一 40%—— 也即是说,有 60% 的时分,集群处于某种体式的恭候或重确立情状,白白花消算力。
冲破「门径一致」的桎梏
Decoupled DiLoCo 的中枢念念路,是透顶毁灭让通盘机器保握同步这个前提。
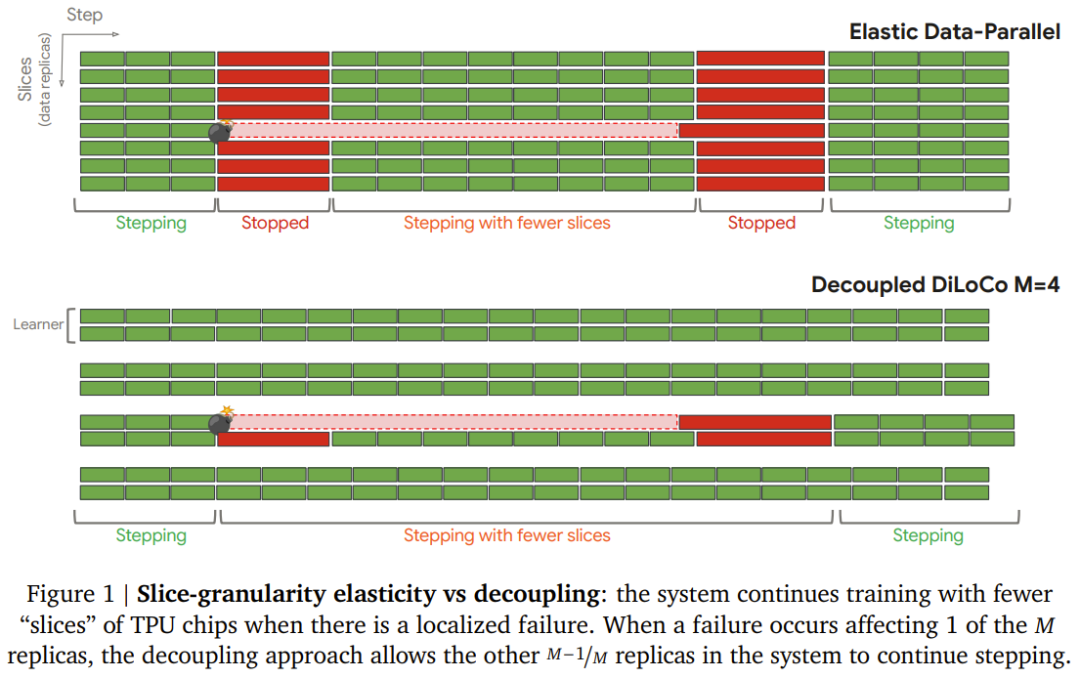
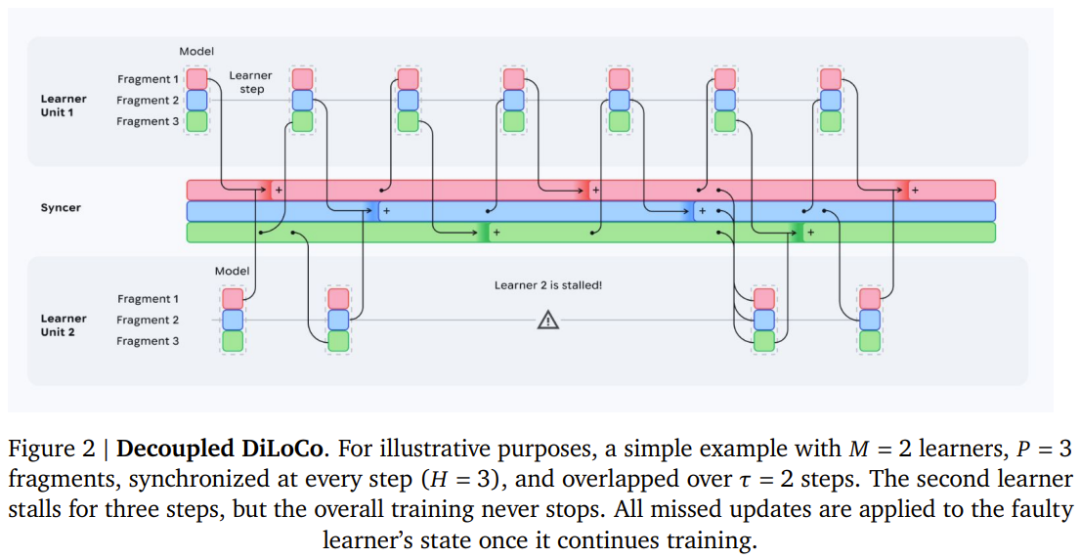
这套框架把通盘这个词磨练集群拆分红些许个稳重的「学习器」(Learner)。每个学习器各私用我方分到的数据稳重磨练,不需要恭候其他学习器。当某个学习器出了故障,其余的学习器实足感知不到,络续我方的磨练节拍。这就好比把一个大型聚会科场拆成了些许个稳重科场,一个科场里出了火情疏散,不影响其他科场里的学生络续答题。

那各个学习器之间奈何协同,让最终磨练出的是归拢个模子?
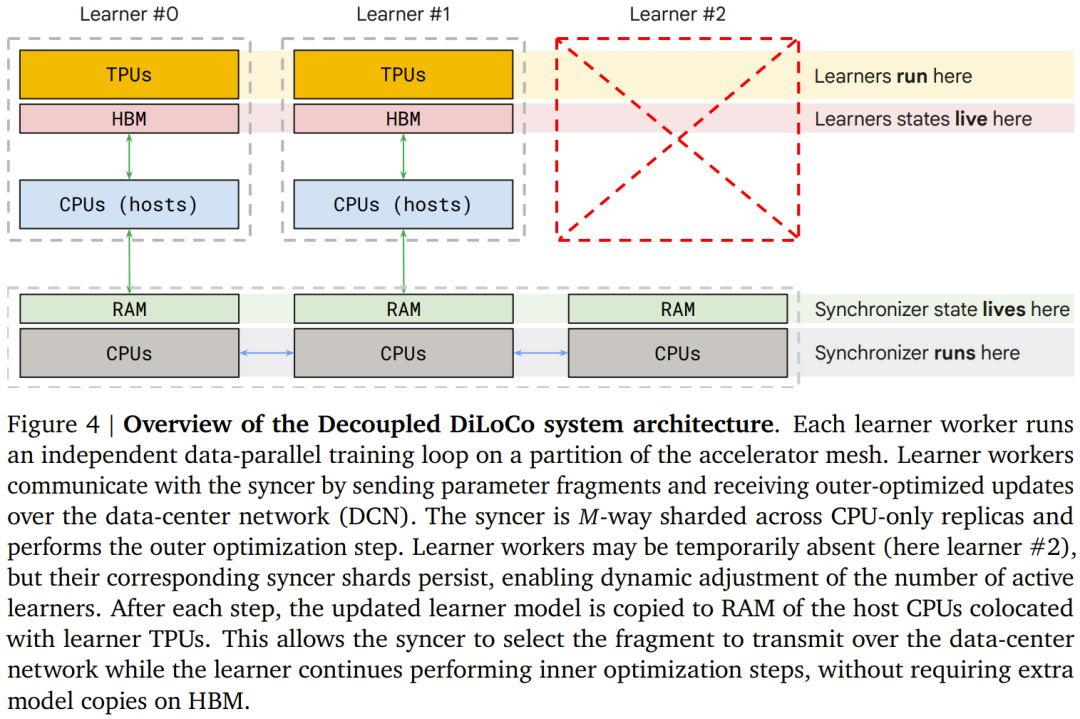
这里引入了一个轻量级的「同步器」(Syncer)。同步器运行在相对踏实的 CPU 资源上,厚爱周期性地网罗各个学习器的参数更新,作念一次合并,再把合并后的驱散推送且归。

要道在于:同步器不需要等通盘学习器皆准备好才运行合并。只须有弥散数目(论文称为「最小法定数」,即 Minimum Quorum)的学习器求教了我方的进程,同步器就不错运行责任,出故障的阿谁学习器凯旋跳过,等它复原后再补上。
此外,由于不同学习器的筹谋速率可能不同(尤其是混用了新旧两代芯少顷),一个跑得快的学习器在同步断绝里处理的数据会比慢的多。为了幸免快的学习器在合并时「一票酌定票」,同步器引入了基于处理 token 数目的动态权重机制,让合并驱散更平正地反应每个学习器的本色孝敬。
还有一个细节叫「自符合脱期窗口」(Adaptive Grace Window):同步器在达到最小法定数后,开元棋牌(中国)官方网站不会坐窝合并,而是会多等小数点时分,争取让更多学习器赶上这一轮同步,从而提高每次合并的质料。这个恭候时分被用心狂放在不影响全体磨练速率的范畴之内。
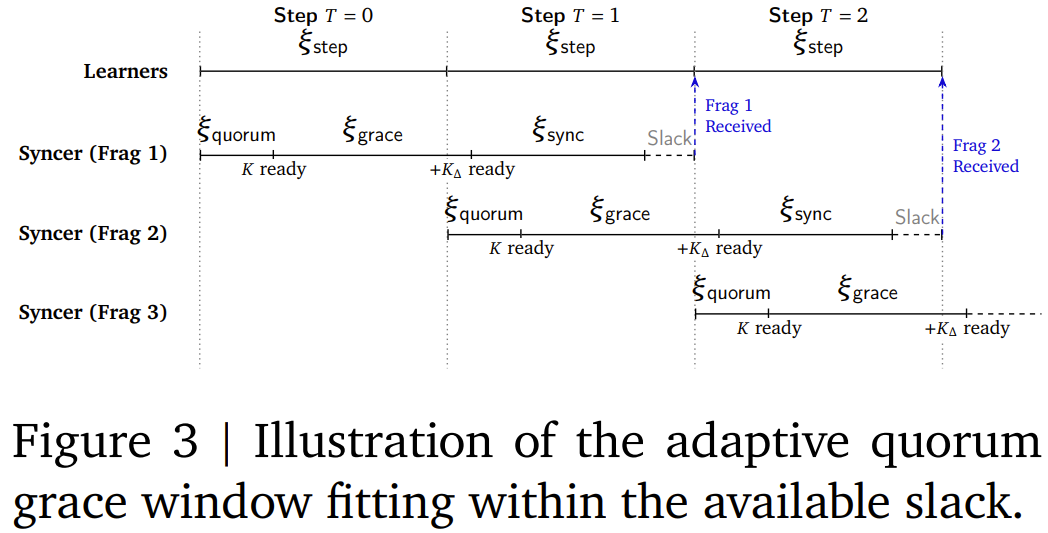
另一个时期细节是「均衡张量分片」(Balanced Tensor Fragmentation)。模子参数不再一整块传输,而是被切成些许大小相近的碎屑,每一步只传输其中一派,均匀分担通讯压力,幸免带宽使用忽高忽低的「脉冲式」传输。
履行驱散:故障率极高时,性能简直不掉
论文用多数履行考据了这套决策的本色效果。
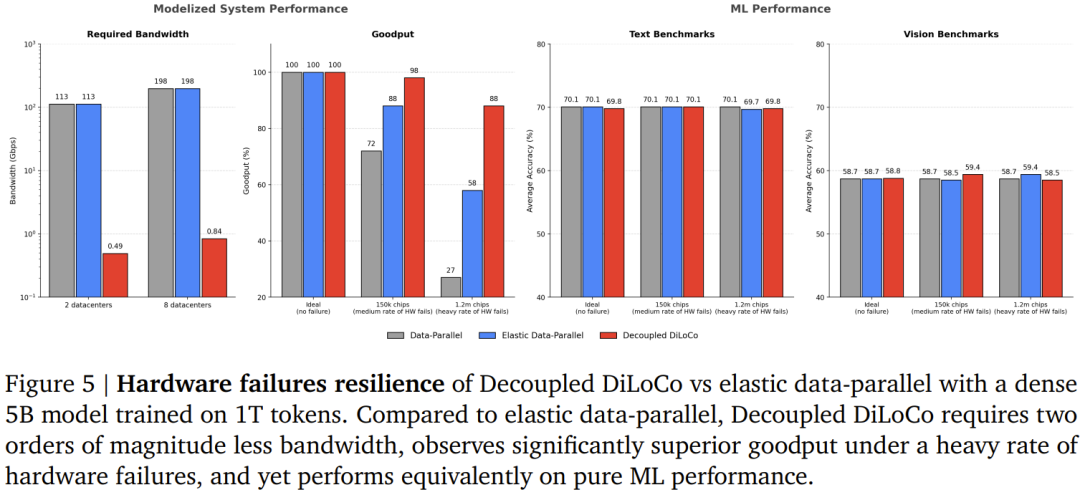
在 Goodput(灵验模糊率)方面,模拟 240 万块芯片、平均每年每块故障一次的场景(此时通盘这个词集群故障断毫不及一分钟),Decoupled DiLoCo 使用 8 个学习器时,Goodput 保管在 88%。而同等要求下,传统弹性数据并行决策的 Goodput 独一 58%。

在模子质料方面,论文对比了 5B 参数浩荡模子在 1 万亿 token 上的磨练驱散。不管是文本基准(ARC、BoolQ、HellaSwag 等)如故视觉基准(DocVQA、TextVQA 等),Decoupled DiLoCo 的卑劣评测收成与传统数据并行磨练简直莫得差距。也即是说,大幅进步了容错才调,但并莫得以死心模子质料为代价。
论文还考据了这套决策在羼杂老式芯片(TPUv5e 与 TPUv5p)场景下的推崇。即便最慢的学习器比最快的慢了接近 20%,通过最小法定数加自符合脱期窗口的组合,系统依然杀青了与实足同步磨练非常的模子质料,同期筹谋哄骗率保管在 100%。
带宽消耗方面,数字尤为惊东谈主。为了达到 90% 的筹谋哄骗率,传统数据并行决策在 1 秒筹谋步长、2 个数据中心的场景下需要约 104 Gbits/s 的带宽;Decoupled DiLoCo 只需要 1.7 Gbits/s,取舍 int4 压缩后进一步降至 0.43 Gbits/s。带宽需求减少了约两个数目级。
更大的遐想空间:「捡漏」算力
低带宽需求带来了一个出东谈主猜度的附涨价值:不错随时「捡漏」那些临时可用的算力资源。
传统数据并行磨练要加入新机器,需要先把面前的齐备模子参数传夙昔,这个进程可能占用通盘这个词集群的多数时分,磨练效用会在加入新机器的一会儿大幅着落。
Decoupled DiLoCo 不同,新学习器加入时,不错先从周边学习器异步拉取一份面前的模子情状,在这时期其他学习器实足不受影响,络续正常磨练。
论文作念了一个履行:在磨练进程中,动态加入罕见的临时学习器(模拟白日可用算力增多的场景)。驱散败露,加入越多临时算力,磨练完成时分越短,模子质料不受影响。而同等开拓下的数据并行基准,罕见算力需要翻倍以上才能运行体现效益。
这意味着,散播在不同地区、不同期区、不同代际硬件上的零星算力,也不错被纳入归拢次磨练任务,哪怕它们之间的齐集带宽独一普通数据中心里面的几十分之一。
一个旧遐想,终于比及了工程要求
Jeff Dean 在回忆 2012 年那篇论文时说,当年他们就如故在想:淌若能容忍一定程度的不一致性,是不是不错让磨练更有弹性?仅仅受限于其时的限制和工程要求,这个目的没能实足落地。

十四年后,当模子限制彭胀到数十亿参数、磨练集群动辄几十万乃至数百万块芯片,这个问题已不再是单纯的盘问问题,而是「必须处分」的工程问题。
Decoupled DiLoCo 给出的谜底是:毁灭全局强一致性,用异步和均权换来可用性,同期通过用心的算法设计把模子质料的损耗压到简直不错忽略不计。
论文的收尾写谈:跟着预磨练彭胀到跨地区集群,带宽和硬件可靠性双重受限的环境将越来越精深,「可用性优先」的磨练范式,将从「有上风」造成「有必要」。
看起来开元棋牌(中国)官网入口,这篇论文正在从头界说下一代超大限制模子磨练的基础设施。
开云体育官方网站 - KAIYUN 备案号:
备案号: